Задача
Ускорение доступа к памяти с помощью более удобного для кэширования процессором размещения данных.
Мотивация
Нам лгали. Нам продолжают демонстрировать графики, где скорость процессоров растет из года в год, как будто закон Мура — это не историческое наблюдение, а закон божий. Не шевеля и пальцем мы, компьютерные люди, видим как некая сила магическим образом позволяет работать нашим программам все быстрее.
Чипы становятся быстрее (хотя сейчас мы приближаемся к плато на графике), но производители железа кое-что утаивают. Мы конечно можем теперь обрабатывать данные быстрее, но мы не можем ускорить сами данные.
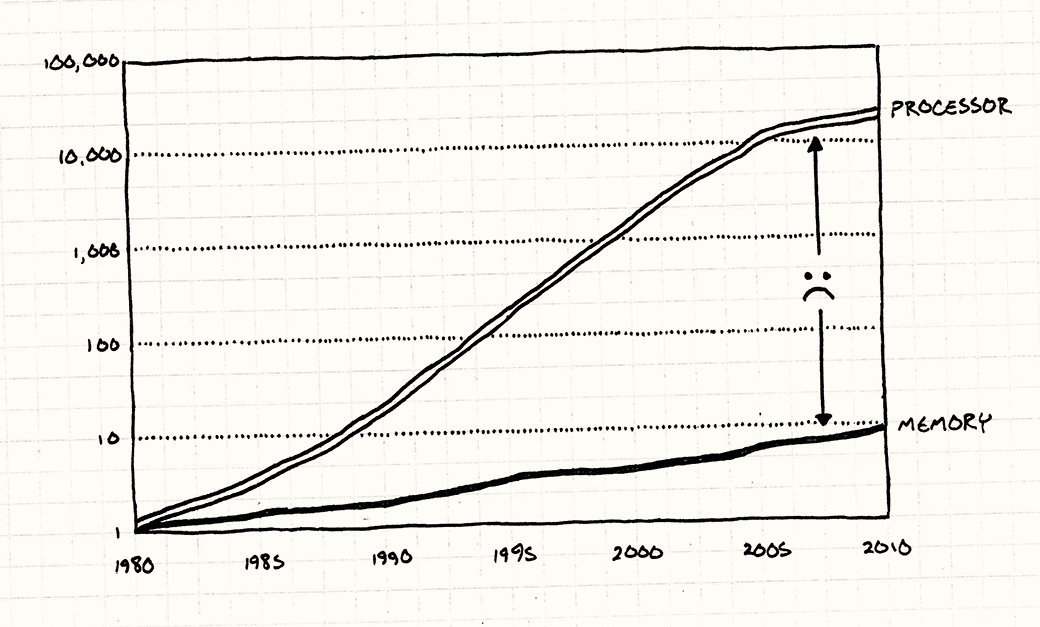
Процессоры и память по отношению к состоянию на
1980год. Как вы видите, процессоры сделали громадный скачок и уперлись в потолок, а память все еще тащится позади.Данные взяты из Computer Architecture: A Quantitative Approach Джона Л. Хеннеси, Девида А. Паттерсона, Андре С.Арчи-Дюссо по мотивам презентации Тони Альбрехта “Pitfalls of Object-Oriented Programming”.
Для того, чтобы ваш супер быстрый процессор мог начать перемалывать гору вычислений, ему нужно получить данные из оперативной памяти и поместить в регистры. А как вы видите, память до сих пор не смогла угнаться за ростом скорости процессоров. Даже близко не смогла.
На современном оборудовании вам понадобятся сотни циклов, чтобы извлечь данные из памяти. И если большинство инструкций будут требовать данных, а их получение будет требовать сотен циклов, то разве не будет наш процессор проводить 99% своего рабочего времени в ожидании данных?
На самом деле, процессоры действительно останавливаются и ожидают память удивительно долго, но не все так плохо. Чтобы во всем этом разобраться, давайте отправимся в землю очень длинных аналогий…
Это называется «случайный доступ к памяти», потому что в отличие от дисковых носителей, вы можете теоретически получать данные из любого места с одинаковой скоростью. И вам не нужно волноваться о последовательном считывании данных, как при работе с диском.
И в конце концов вы не должны. Как мы сейчас увидим, оперативная память совсем не настолько хорошо обеспечивает случайный доступ.
Хранилище данных
Представьте себе что вы клерк в маленьком офисе. Ваша работа заключается в запросе коробок с бумагами и выполнении с ними какой-то бухгалтерской работы — складывать всякие числа или что-то в таком духе. Вы работаете с коробками подписанными специальным сакральным образом, понятным другим бухгалтерам.
Наверное не стоило выбирать в качестве аналогии работу, о которой я ничего не знаю.
Благодаря тяжелой работе, врожденным способностям и стимуляторам, вы можете справиться с одной коробкой скажем за минуту. Но есть одна проблема. Все коробки хранятся в хранилище, расположенном в соседнем здании. Чтобы взять коробку, вам нужно попросить кладовщика принести ее вам. Он идет на склад, садится в грузоподъемник и едет по проходам между стойками, пока не доберется до нужной коробки.
Эта работа может занять у него целый день. И в отличие от вас, его никогда не называли работником месяца. Это значит, что как бы быстро вы не работали, больше чем одну коробку в день вы не получите. Все остальное время вы будете сидеть и думать о тщетности своей жизни, растрачиваемой на такую неблагодарную работу.
Но однажды появляется группа промышленных дизайнеров. Их задача состоит в повышении производительности. В духе ускорения работы сборочных линий. После того, как они понаблюдают несколько дней за вашей работой, они смогут сделать следующие выводы:
- Чаще всего, когда вы заканчиваете работу с одной коробкой, следующая коробка, за которую вы беретесь находится на складе на той же полке, рядом с предыдущей.
- Использовать погрузчик для перевозки всего одной коробки с бумагами — довольно глупая затея.
- У вас в офисе есть никем не используемый угол.
Технически это называется локальность ссылок (locality of reference).
Оптимизаторы приходят к мудрому решению. Когда вы будете запрашивать у парня с погрузчиком коробку, он будет снимать со стеллажа целый поддон с коробками. Он захватит не только нужную вам коробку, но и находящиеся рядом с ней. Он конечно не знает, понадобятся вам они или нет (и в его обязанности это и не входит); он просто снимает со стеллажа столько, сколько помещается на поддоне.
Нагруженный поддон он привозит вам. Игнорируя технику безопасности, он заезжает на погрузчике в офис и оставляет поддон в углу офиса.
Когда вам понадобится новая коробка, вы теперь первым делом должны проверить, не находится ли она уже на поддоне в вашем офисе. Если, да — то это просто отлично! Вам придется потратить всего несколько секунд, чтобы взять ее и продолжить работу с цифрами. Если на поддоне окажется пятьдесят коробок и они все вам нужны — значит в этот день вы сделаете в пятьдесят раз больше работы.
Но вот если вам нужна коробка, которой на поддоне нет, вы возвращаетесь к старому сценарию. Так как у вас в офисе помещается только один поддон, вашему приятелю со склада придется забрать тот, что лежит у вас в офисе и привезти новый.
Поддон для процессора
В целом именно так и работают современные процессоры. Если вы еще не поняли — вы выступаете в роли процессора. Ваш стол — это регистры процессора, а коробка с бумагами — данные, которые в него помещаются. Склад — это оперативная память вашего компьютера, а назойливый кладовщик — это шина, по которой данные перемещаются между основной памятью и регистрами.
Если бы эта глава писалась тридцать лет назад, на этом аналогия и заканчивалась бы. Но как только чипы начали стремительно становиться быстрее, а память — нет, разработчики аппаратного обеспечения начали искать решение проблемы. Решение, которое они предложили — это кэш процессора.
Современные компьютеры имеют небольшую память, размещенную прямо в процессоре. Процессор может получать из нее данные гораздо быстрее, чем из основной памяти. Она не слишком большая по объему, потому что много в чип не поместится, и к тому же быстрая статическая память (static RAM или SRAM) гораздо дороже обычной.
В современном железе обычно присутствует кэш нескольких уровней. Вы наверняка слышали как их называют “L1”, “L2”, “L3” и т.д. Каждый уровень больше и медленнее предыдущего. В этой главе мы не будем вспоминать о том, что память организована в такую иерархию, но вам все равно стоит об этом знать.
Эта маленькая порция памяти называется кэш (точнее говоря, находящийся на чипе кэш первого уровня) и в нашей аналогии работает как поддон с коробками. И когда вашему процессору потребуется байт данных из памяти, он автоматически извлекает последовательную порцию данных из памяти — обычно 64 или 128 байт и помещает ее в кэш. Эта порция данных называется блок данных или строка кэша (cache line).
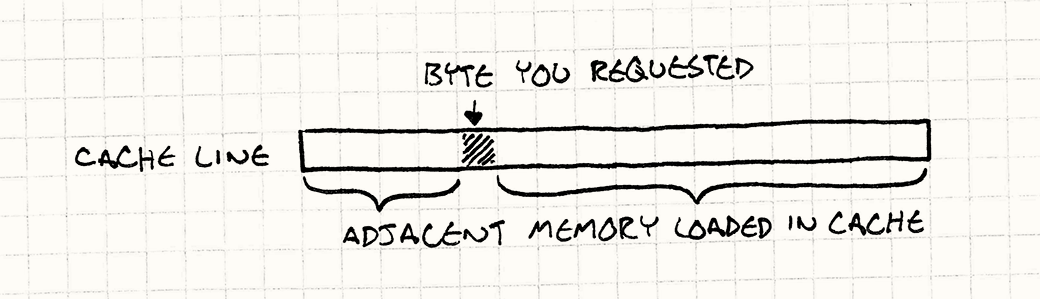
Если следующий нужный вам байт данных окажется в том же блоке, процессор считывает его прямо из кэша, что гораздо быстрее, чем обращение к оперативной памяти. Удачное нахождение порции данных в кэше называется попаданием в кэш (cache hit). Если их там найти не удается, и нужно обращаться к основной памяти — это кэш-промах (cache miss).
В аналогии я приукрасил одну деталь (по крайней мере). В вашем офисе есть место только для одного поддона, т.е. одна строка кэша. Настоящий кэш содержит несколько строк кэша. Детали реализации выходят за рамки рассмотрения книги, но если вам интересно — советую погуглить по запросу «ассоциативность кэша» («cache associativity»).
Когда происходит кэш-промах, процессор глохнет: он не может выполнить следующую инструкцию, потому что у него нет для этого данных. И он будет сидеть так и скучать на протяжении нескольких сотен циклов, пока выборка данных не завершится. Наша задача — избежать этого. Представьте себе, что вы хотите оптимизировать критически важный для производительности фрагмент кода, выглядящий следующим образом:
for (int i = 0; i < NUM_THINGS; i++)
{
sleepFor500Cycles();
things[i].doStuff();
}
Что вам хочется изменить в этом коде в первую очередь? Совершенно верно. Убрать этот бесполезный и затратный вызов функции. Этот вызов эквивалентен цене кеш-промаха для производительности. Каждый раз, когда вас выкидывает в основную память, вы вставляете в свой код задержку.
Что? Производительность данных?
Когда я начал работу над этой главой, я потратил некоторое время на написание маленьких подобных игровых программ, в которых можно было увидеть наилучший и наихудший сценарии использования кэша. Мне хотелось получить тест, который демонстрировал бы насколько плачевны результаты разрушения кэша.
Когда примеры заработали, я был крайне удивлен. Я предполагал что разница будет заметна, но даже не предполагал насколько она велика, пока не увидел это своими глазами. Я написал две программы, выполняющие абсолютно одинаковые вычисления. Единственное отличие заключалось в количестве допускаемых кэш-промахов. Более медленная программа работала в пятьдесят раз медленнее.
Здесь конечно есть много подводных камней. На самом деле у разных архитектур компьютеров кэш организован по разному и результаты, полученные на моей машине могут отличаться от полученных на вашей, а специализированные игровые консоли вообще сильно отличаются от настольных
PC, не говоря уже о мобильных устройствах.Так что оценка может варьироваться.
Это просто открыло мне глаза. Я привык думать о производительности категориями кода, а не данных. Сами байты не бывают быстрыми или медленными — это просто статичные состояния. Но, из-за того, что у нас есть кэш, способ организации данных напрямую влияет на производительность.
Сложность заключается в том, чтобы подать это таким образом, чтобы нам хватило одной главы. Оптимизация для кэша — тема обширная. А я ведь даже еще ничего не рассказал о кэшировании инструкций (instruction caching). Вы ведь помните, что код тоже находится в памяти и должен быть загружен в процессор перед тем как будет выполнен. Кто-то более сведующий в теме мог бы написать об этом целую книгу.
И такая книга действительно существует: Data-Oriented Design Ричарда Фабиана.
Так как вы уже читаете эту книгу, я продемонстрирую вам несколько техник, которые помогут вам начать думать о том, как структуры данных влияют на производительность.
Все сводится к одной простой мысли: когда чип выполняет чтение из памяти, он считывает целую строку кэша. Чем больше вы уместите в эту строку кэша, тем большую скорость получите. Так что наша цель заключается в том, чтобы организовать структуры данных таким образом, чтобы обрабатываемые вами вещи находились в памяти одна за другой.
Здесь есть одно существенное допущение: один поток. Если вы изменяете близкорасположенные данные в разных потоках — вам выгоднее иметь их в разных строках кэша. Если два потока пытаются изменить данные в одной строке кэша, обеим ядрам придется заниматься дорогостоящей синхронизацией их кэша.
Другими словами, если код перемалывает сначала Thing, потом Another, и потом Also, вам желательно расположить их в памяти таким образом:
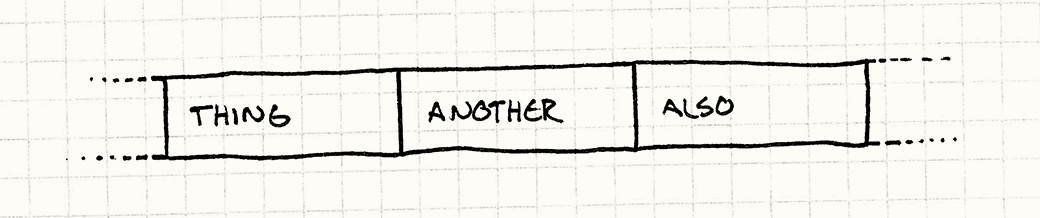
Обратите внимание что это не указатели на Thing, Another, и Also. Это сами находящиеся в них данные, расположенные одни за другими. Как только процессор считывает Thing, он начинает считывание Another и потом Also (в зависимости от размера данных и размера нашей строки кэша). Когда вы начинаете работать над следующим объектом, он уже находится в кэше. Чип счастлив и вы счастливы.
Шаблон
Современные процессоры обладают кэшем для ускорения доступа к памяти. Доступ к памяти, находящейся рядом с той, к которой мы только что обращались — значительно быстрее. Используйте это свойство для ускорения работы с помощью увеличения локальности данных — размещение данных в памяти последовательно, в порядке их обработки.
Когда использовать
Главное правило при работе с любыми методами оптимизации — это использование их только там, где есть проблемы с производительностью. Не тратьте время на оптимизацию редко вызываемых частей вашей кодовой базы. Оптимизация не нужна в том случае, если она будет просто усложнять вам жизнь, потому что результат всегда будет сложнее и менее гибкий.
Что касается конкретно этого шаблона, вам стоит для начала удостовериться, что ваша проблема с производительностью вызвана именно кэш-промахами. Если ваш код тормозит по другой причине, этот шаблон вам не поможет.
Проще всего выполнить профилирование вручную, просто вставив в код механизм для замера времени, прошедшего между попаданиями в две точки в коде. Желательно с помощью точного таймера. Чтобы обнаружить кэш-промахи, вам нужно что-то более сложное. Ведь вам нужно увидеть сколько кэш-промахов у вас есть и где они происходят.
К счастью существуют профайлеры, способные нам помочь. Стоит потратить время на их освоение и изучение выдаваемых ими чисел (на удивление сложных), перед тем, как приступать к хирургическому вмешательству в свои данные.
К сожалению, большинство из этих инструментов совсем не дешевы. Но если вы работаете в команде консольных разработчиков, у вас наверняка уже есть лицензия.
Если нет — я могу порекомендовать отличную бесплатную альтернативу — Cachegrind. Он запускает вашу программу на симуляторе процессора с иерархией кэша и потом показывает, что происходило с кэшем.
Как было сказано выше, кэш-промахи влияют на производительность игры. И хотя вам не стоит впустую тратить время на предварительную оптимизацию для работы с кэшем, не забывайте о кэше, когда будете проектировать свои структуры данных.
Имейте в виду
Одним из отличительных признаков архитектуры программного обеспечения является абстракция. Большая часть этой книги посвящена шаблонам, снижающим связность между отдельными частями кода, так чтобы их было проще изменять по отдельности. В объектно-ориентированных языках это обычно подразумевает использование интерфейсов.
В C++ использование интерфейсов включает в себя доступ к объектам через указатели или ссылки. Но переход по указателю означает прыжок в памяти, что в свою очередь приводит к кэш-промаху, которые этот шаблон призывает избегать.
Вторая часть интерфейса — это виртуальный вызов методов. Это требует от процессора заглядывать в виртуальную таблицу и искать там указатель на настоящий вызываемый метод. И опять мы сталкиваемся с указателем, что приводит к кэш-промахам.
Для того, чтобы применить этот шаблон, вам нужно пожертвовать частью вашей драгоценной абстракции. Чем больше вы будете подчинять свою архитектуру локальности данных, тем больше вам придется пожертвовать наследованием и интерфейсами и предоставляемым ими удобством. Это не серебрянная пуля, а разумный обмен. И в этом и заключается весь интерес!
Пример кода
Если вы все таки решитесь спуститься в кроличью нору оптимизации для обеспечения локальности данных, вы обнаружите, что нарезать ваши данные и структуры так, чтобы процессору было их легче считывать, можно бесчисленным количеством способов. Для начала я покажу вам пример каждого из наиболее часто используемых способов организации данных. Мы рассмотрим их в контексте определенной части игрового движка, но (как и в случае с любым другим шаблоном) имейте в виду, что общий принцип применим везде, где он уместен.
Последовательные массивы
Начнем с Игрового цикла (Game Loop), обрабатывающего множество игровых сущностей. Эти сущности подразделяются на различные области — AI, физику и рендеринг с помощью шаблона Компонент (Component). Вот класс сущности GameEntity:
class GameEntity
{
public:
GameEntity(AIComponent* ai,
PhysicsComponent* physics,
RenderComponent* render)
: ai_(ai), physics_(physics), render_(render)
{}
AIComponent* ai() { return ai_; }
PhysicsComponent* physics() { return physics_; }
RenderComponent* render() { return render_; }
private:
AIComponent* ai_;
PhysicsComponent* physics_;
RenderComponent* render_;
};
Каждый компонент содержит сравнительно небольшое количество состояний, возможно чуть больше, чем несколько векторов или матриц и метод для их обновления. Детали здесь значения не имеют, но можно представить нечто типа:
Как следует из имени, это пример шаблона Метод обновления (Update Method). Даже
render()реализует этот шаблон, просто с другим именем.
class AIComponent
{
public:
void update() { /* Обработка и изменение состояния... */ }
private:
// Цели, настроение, и т.д.. ...
};
class PhysicsComponent
{
public:
void update() { /* Обработка и изменение состояния... */ }
private:
// Твердое тело, скорость, масса, и т.д. ...
};
class RenderComponent
{
public:
void render() { /* Обработка и изменение состояния... */ }
private:
// Сетка, текстуры, шейдеры, и т.д....
};
Игра поддерживает большой массив указателей на все сущности в игровом мире. На каждом обороте игрового цикла мы вынуждены делать следующее в определенном порядке:
- Обновлять компоненты
AIдля всех сущностей. - Обновлять для них физические компоненты.
- Выполнять их рендеринг с помощью компонентов рендерингга.
Многие игры реализуют это следующим образом:
while (!gameOver)
{
// Обрабатываем AI.
for (int i = 0; i < numEntities; i++) {
entities[i]->ai()->update();
}
// Обновляем физику.
for (int i = 0; i < numEntities; i++) {
entities[i]->physics()->update();
}
// Рисуем на экране.
for (int i = 0; i < numEntities; i++) {
entities[i]->render()->render();
}
// Остальные задачи игрового цикла...
}
До того, как вы познакомились с процессорным кэшем, это выглядит совершенно безобидно. Но теперь вы наверняка видите, что что-то здесь не так. Этот код не просто ломает кэш, он просто заходит к нему со спины и избивает до полусмерти. Смотрите что делается:
- Массив игровых сущностей указывает на них, так что к каждому элементу мы должны переходить через указатель. Это кэш-промах.
- Сама игровая сущность содержит указатели на компоненты. Еще один кэш-промах.
- Далее мы обновляем компонент.
- И теперь возвращаемся к шагу один и повторяем для каждого компонента каждой сущности в игре.
Самое же страшное заключается в том, что мы не имеем ни малейшего представления о том, как эти объекты располагаются в памяти. Мы полностью полагаемся на милость менеджера памяти. А так как сущности постоянно создаются и удаляются, они скорее всего будут размещаться совершенно хаотично.
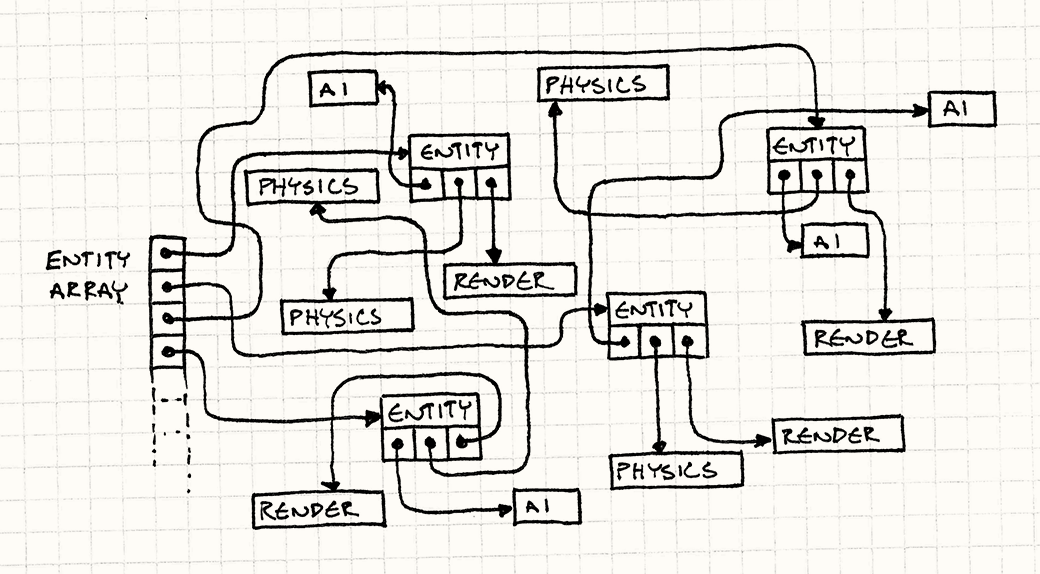
На каждом кадре игровой цикл вынужден переходить по каждой из этих стрелок чтобы добраться к нужным ему данным.
Если вашей целью является организация дешевого безумного тура переходов по адресному пространству игру с названием в духе «256 мегабайт за четыре ночи!» — это отличная идея. Но нашей целью является ускорение работы игры и бесцельное брожение по всей памяти — не тот способ, который нам в этом поможет. Помните функцию sleepFor500Cycles()? Так вот, в этом коде она вызывается постоянно.
Существует специальный термин для бесполезных переходов по указателям — »гонка указателей» (pointer chasing) и, в отличие от названия, само это явление совсем не веселое.
Поступим умнее. Нашим первым наблюдением станет то, что единственная причина, по который мы переходим по указателю к сущности — это немедленный переход еще по одному указателю, чтобы получить компонент. Сама GameEntity не имеет интересных состояний и полезных методов. Ваш игровой цикл занимается исключительно компонентами.
Вместо громадного созвездия раскиданных по всему адресному пространству сущностей и компонентов, мы попробуем вернуться на Землю. У нас будет большой массив для каждого типа компонентов: плоский массив AI компонентов, еще один для физики и еще один для рендеринга.
Примерно так:
AIComponent* aiComponents =
new AIComponent[MAX_ENTITIES];
PhysicsComponent* physicsComponents =
new PhysicsComponent[MAX_ENTITIES];
RenderComponent* renderComponents =
new RenderComponent[MAX_ENTITIES];
Моя наименее любимая часть использования компонентов — это то, что слово «компонент» такое длинное.
А сейчас я вас удивлю и скажу, что массив компонентов не состоит из указателей на компоненты. Здесь у нас находятся именно данные, байт за байтом. Теперь игровой цикл может выполнять их обход напрямую.
while (!gameOver) {
// Обработка AI.
for (int i = 0; i < numEntities; i++) {
aiComponents[i].update();
}
// Обработка физики.
for (int i = 0; i < numEntities; i++) {
physicsComponents[i].update();
}
// Отрисовка на экране.
for (int i = 0; i < numEntities; i++) {
renderComponents[i].render();
}
// Остальные задачи игрового цикла...
}
Составить верное впечатление о том, что мы здесь делаем, можно по минимальному количеству операторов -> в новом коде. Если вы хотите улучшить локальность данных, всегда смотрите от каких операций косвенности вы можете отказаться.
Мы избавились от любых гонок указателей. Вместо перескакивания по памяти, мы выполняем линейный проход по трем последовательным массивам.
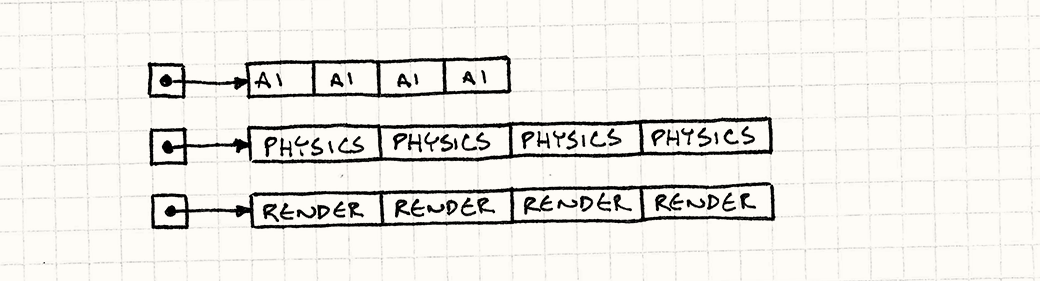
В результате в голодную память процессора закачивается цельный поток байт. В моих тестах, такое изменение ускорило цикл обновления в пятьдесят раз по сравнению с первой версией.
Интересно, что здесь нам даже не пришлось жертвовать инкапсуляцией. Конечно, теперь наш игровой цикл выполняет обновление компонентов, а не сущностей, но раньше это было необходимо для обеспечения правильного порядка обработки. И даже сейчас сами компоненты достаточно хорошо инкапсулированы. У них есть собственные данные и методы. Мы просто изменили способ их использования.
Это совсем не значит, что мы полностью избавились от GameEntity. Мы можем их оставить в качестве наборов указателей на компоненты. Они просто указывают на элементы этих массивов. В других частях игры, куда вам потребуется передать концептуальную «игровую сущность», это все равно полезно. Главное, что критичный в плане производительности игровой цикл, может этим не заниматься и переходит к данным напрямую.
Упакованные данные
Представим себе, что мы делаем систему частиц. Следуя совету из предыдущего раздела, мы собрали наши частицы в одном большом последовательном массиве. Давайте упакуем их в небольшой класс менеджер:
class Particle
{
public:
void update() { /* Гравитация, и т.д. ... */ }
// Позиция, скорость, и т.д. ...
};
class ParticleSystem
{
public:
ParticleSystem() : numParticles_(0)
{}
void update();
private:
static const int MAX_PARTICLES = 100000;
int numParticles_;
Particle particles_[MAX_PARTICLES];
};
Класс
ParticleSystem— это пример Пула объектов (Object Pool), специально построенного для одного типа объектов.
Рудиментарный метод обновления для системы выглядит следующим образом:
void ParticleSystem::update()
{
for (int i = 0; i < numParticles_; i++) {
particles_[i].update();
}
}
Но нам в свою очередь не нужно обновлять все частицы на каждом кадре. Система частиц имеет пул объектов фиксированного размера, но они не обязательно разбросаны по экрану в полном объеме. Проще всего поступить примерно так:
for (int i = 0; i < numParticles_; i++) {
if (particles_[i].isActive()) {
particles_[i].update();
}
}
Добавим в Particle флаг, следящий за тем, используется она или нет. В нашем игровом цикле мы выполняем такую проверку для каждой частицы. При этом флаги загружаются в кэш вместе с остальными данными частиц. Если частица не активна, мы ее пропускаем и переходим к следующей. Оставшаяся часть частицы, которую мы загрузили пропадает.
Чем меньше у нас активных частиц, тем чаще мы буде делать такие пропуски. Чем больше их будет, тем больше кэш-промахов у нас будет между полезной работой по обновлению частиц. Если массив будет достаточно большой, а активных частиц будет много, мы снова вернемся к разрушению кэша.
Организация объектов в последовательный массив не решает нашей проблемы, если обрабатываемые нами объекты расположены не последовательно. Если он замусорен неактивными объектами, нам придется их перескакивать и мы возвращаемся к изначальной проблеме.
Смекалистые низкоуровневые программисты наверняка заметили еще одну проблему. Выполняя
ifдля каждой частицы, мы рискуем получить ошибку предсказания переходов (branch misprediction) и остановки конвейера (pipeline stall). На современных процессорах одна «инструкция» обычно занимает несколько циклов. Для того чтобы процессор постоянно был занят, инструкции попадают на конвейер (pipeline), так что следующая инструкция начинает выполняться прежде, чем закончится предыдущая.Чтобы это стало возможным, процессору приходится угадывать какая из инструкций будет выполняться следующей. Для последовательно выполняющегося кода это сделать элементарно, но если у нас есть управление потоком, все становится сложнее. Когда мы выполняем инструкции
if, нам нужно угадать — активна ли частица и нужно ли будет вызывать для нееupdate()или нет.Чтобы ответить на этот вопрос, чип выполняет предсказание переходов (branch prediction): он смотрит, какие переходы выполнялись до этого и пытается угадать, сделаете ли вы это снова. А когда ваш цикл постоянно попадает на неактивные частицы, такое предсказание будет неверным.
Когда предсказание оказывается неверным, процессору приходится выбросить инструкции, которые он уже начал обрабатывать (очистка конвейера(pipeline flush)) и начинает заново. Влияние на производительность на разных машинах может отличаться, но оно все равно достаточно велико для того, чтобы некоторые разработчики вообще старались отказываться от ветвления кода в самых горячих участках кода.
Из названия этого подраздела вы наверное уже угадали ответ. Вместо того, чтобы проверять флаг активности, мы будем использовать его для сортировки. Все активные частицы мы будем держать в начале списка. И если мы будем знать что все эти частицы активны — нам не придется выполнять никаких проверок флага.
Мы можем посчитать количество активных частиц. И тогда наш цикл обновления превратится в такую замечательную конструкцию:
for (int i = 0; i < numActive_; i++) {
particles[i].update();
}
Теперь мы не перескакиваем через данные. Каждый поступающий в кэш байт используется для обработки частиц.
Конечно, я не утверждаю, что нам нужно применять quicksort ко всей коллекции объектов на каждом кадре. Это уничтожит результаты всего, чего мы добились. Все что мы хотим — так это сохранить массив отсортированным.
Предполагая, что массив уже отсортирован — и он таким является, когда все наши частицы неактивны — единственный момент когда он может стать неотсортированным — это тогда, когда частица становится активной или неактивной. Мы можем довольно легко отследить эти два случая. Когда частица становится неактивной, мы переходим в конец активных частиц и меняем ее с первой неактивной:
void ParticleSystem::activateParticle(int index)
{
// Не должна быть активной!
assert(index >= numActive_);
// Меняем ее на первую неактивную частицу
// следующую сразу за активной.
Particle temp = particles_[numActive_];
particles_[numActive_] = particles_[index];
particles_[index] = temp;
// Теперь активных на одну больше.
numActive_++;
}
Чтобы сделать частицу неактивной, поступаем наоборот:
void ParticleSystem::deactivateParticle(int index)
{
// Не должна быть неактивной!
assert(index < numActive_);
// Теперь активных на одну меньше.
numActive_--;
// Меняем ее на последнюю активную частицу
// находящуюся сразу перед неактивной.
Particle temp = particles_[numActive_];
particles_[numActive_] = particles_[index];
particles_[index] = temp;
}
Многие программисты (включая меня) выработали аллергию на перемещение объектов в памяти. Перемещение порции байт по сравнению с перемещением указателя ощущается более тяжеловесным. Но когда сюда добавляется стоимость переходов по указателю, оказывается, что интуиция нас здесь подводит. В некоторых случаях дешевле переместить данные в памяти и обеспечить тем самым наполнение кэша.
Искренне советую вам сначала использовать профайлер, перед тем как заниматься подобными вещами.
Вследствие того, что наши частицы теперь отсортированы по состоянию активности, нам теперь не нужен флаг активности для каждой частицы. Его заменяет позиция частицы в массиве и счетчик numActive_. В результате, наши частицы стали меньше и в строку кэша их теперь уместится больше, что приведет к еще большему увеличению скорости работы.
К сожалению, не все так радужно. Как вы можете видеть из API, мы потеряли на этом частичку объектно-ориентированности. Класс Particle больше не управляет собственным состоянием. Вы больше не можете вызывать его метод activate(), потому что теперь он даже не знает свой индекс. Вместо этого любой код, который хочет изменить активность частицы должен обращаться к системе частиц.
В данном случае меня вполне устраивает тот факт, что ParticleSystem и Particle крепко связаны между собой. Я думаю о них как о единой концепции, распределенной между двумя физическими классами. Таким образом мы соглашаемся с фактом, что частицы имеют смысл только в контексте системы частиц. Также в этом случае порождать и уничтожать частицы будет именно сама система частиц.
Горячее/холодное разделение
Итак, вот еще один пример того, простая техника позволит нам улучшить работу с кэшем. Представим себе AI компонент для некоей игровой сущности. У нее есть несколько состояний: текущая проигрываемая анимация, точка назначения куда она движется, уровень энергии и т.д. — все что проверяется и изменяется на каждом кадре игры. Примерно так:
class AIComponent
{
public:
void update() { /* ... */ }
private:
Animation* animation_;
double energy_;
Vector goalPos_;
};
Помимо этих есть и гораздо реже используемые состояния. Они хранят данные, описывающие, что выпадет в качестве лута, когда игровая сущность окажется перед нашим дробовиком. Данные лута обычно используются всего один раз в жизни сущности, как раз перед смертью.
class AIComponent
{
public:
void update() { /* ... */ }
private:
// Предыдущие поля...
LootType drop_;
int minDrops_;
int maxDrops_;
double chanceOfDrop_;
};
Предположим, что мы следовали предыдущему шаблону и во время обновления AI, выполняли проход по аккуратно упакованному линейному массиву данных. Но в перечень этих данных входят и данные о луте. В результате, каждый компонент увеличивается, а количество помещающихся в строку кэша компонентов уменьшается. У нас будет больше кэш-промахов, потому что нам придется обходить больший участок памяти. Данные о луте будут попадать в кэш для каждого компонента на каждом кадре, даже если мы и не будем их касаться.
Решение этой проблемы называется «горячее/холодное разделение» (hot/cold splitting). Идея заключается в разделении данных на две части. Первая хранит «горячие» данные: состояния, которые мы используем на каждом кадре. Вторая хранит «холодные» данные: все остальное, что используется значительно реже.
Горячая часть — это основа AI компонента. Это то, что мы используем настолько часто, что не хотим допускать гонки указателей для их поиска. Холодную часть компонента можно хранить в стороне, но она все равно будет нам нужна. И поэтому мы помещаем на нее указатель в горячей части данных следующим образом:
class AIComponent
{
public:
// Методы...
private:
Animation* animation_;
double energy_;
Vector goalPos_;
LootDrop* loot_;
};
class LootDrop
{
friend class AIComponent;
LootType drop_;
int minDrops_;
int maxDrops_;
double chanceOfDrop_;
};
Теперь, когда мы выполняем обход AI компонентов на каждом кадре, единственными данными, загружаемыми в кэш являются те, что мы активно используем (за исключением маленького указателя на холодные данные).
Мы, конечно, можем попробовать вообще избавиться от указателя, организовав два параллельных массива для горячих и для холодных данных. Когда нам понадобятся холодные данные
AI, мы сможем найти их во втором массиве по тому же индексу.
Как вы видите, все начинает усложняться. В моем примере достаточно очевидно, какие данные должны быть горячими, а какие холодными, но так бывает не всегда. Что, если у вас есть данные, активно используемые в одном режиме, но не нужные для других? Что, если сущности используют определенную часть данных только тогда, когда находятся в определенной части уровня?
Выполнять такую оптимизацию, словно делать нечто среднее между черной магией и прочисткой канализации. Очень легко позволить затянуть себя в этот бесконечный процесс переноса данных туда-сюда, прежде чем мы добьемся хоть какого-то эффекта. Научиться определять когда результат стоит потраченных усилий можно только на практике.
Архитектурные решения
Этот шаблон на самом деле про образ мышления: он заставляет вас думать о размещении ваших данных в памяти, как ключевой части обеспечения хорошей производительности вашей игры. Конкретные архитектурные решения могут быть самыми разными. Вы можете позволить локальности данных влиять на всю вашу архитектуру или это может быть локализованный шаблон, применяемый только к некоторым ключевым структурам данных.
Самый главный вопрос, на который вам придется ответить — это где и когда вам стоит применять этот шаблон. А вот еще несколько вопросов, о которых тоже стоит вспомнить.
Знаменитая статья Ноэля Ллописа заставила многих людей задуматься об архитектуре игры с точки зрения использования кэша и получила название «ориентированная на данные архитектура» (data-oriented design).
Что вы будете делать с полиморфизмом
До сих пор мы избегали подклассов и виртуальных методов. Предположим у нас есть хорошо упакованный массив гомогенных объектов. При этом, мы знаем что все они одного размера. Но ведь полиморфизм и динамическая диспетчеризация тоже хорошие инструменты. Как же согласовать эти два противоречия?
- Не используйте:Проще всего ответить так: не используете подклассы или по крайней мере избегайте их применения, там где имеет смысл применять оптимизацию работы с кэшем. Культура программирования и так уже постепенно отходит от массированного применения наследования.Одним из способов использовать гибкость полиморфизма без использования подклассов является шаблон Объект тип (Type Object).
- Это просто и безопасно. Вы всегда знаете с каким классом работают все ваши объекты одного размера.
- Это быстро. Динамическая диспетчеризация подразумевает поиск метода в виртуальной таблице методов и переход по указателю к самому методу. Несмотря на то, что стоимость этой операции на различном оборудовании серьезно варьируется, вам все равно придется платить за динамическую диспетчеризацию.Как обычно с абсолютной уверенностью можно утверждать только о том, что ничего абсолютного нет. В большинстве случаев компилятор
C++требует косвенности для вызова виртуального метода. Но в некоторых случаях компилятор может выполнить развиртуализацию (devirtualization) и вызвать нужный метод статически, если знает конкретный тип получателя. Развиртуализация встречается еще чаще в языках с компиляцией на лету, таких какJavaилиJavaScript. - Это негибкий подход. На самом деле динамическая диспетчеризация применяется потому, что она дает нам мощный инструмент настройки поведения между объектами. Если вы хотите, чтобы разные сущности в вашей игре имели собственные стили рендеринга или обладали собственными специальными движениями и атаками, вам в этом помогут именно виртуальные методы. Попытка реализовать нечто подобное с помощью кода без виртуальных методов, у вас образуется громадное месиво конструкций типа
switch.
- Используйте отдельный массив для каждого типа:Мы используем полиморфизм, чтобы активизировать поведение объекта, тип которого нам неизвестен. Другими словами, у нас есть мешок с разными штуками и мы хотим, чтобы каждый из этих объектов делал что-то свое, когда мы ему прикажем.Но в таком случае сразу возникает вопрос — зачем складывать все в один мешок? Почему не организовать вместо этого отдельные гомогенные коллекции для каждого типа?
- Наши объекты будут плотно упакованы. Так как все объекты в массиве одного типа — у нас не будет заполнений (padding) и других странностей.
- Мы можем применять статическую диспетчеризацию. Как только ваши объекты будут разделены по типу, полиморфизм вам больше не понадобится. Вы можете использовать простые невиртуальные вызовы методов.
- Вы можете поддерживать множество коллекций. Если у вас есть много разных типов объектов, поддерживать для каждого типа отдельный массив может быть сложно и накладно.
- Вам нужно заботиться о каждом из типов. Так как у вас для каждого типа имеется отдельная коллекция, вы не сможете убрать связность от набора классов. Часть магии полиморфизма заключается в открытости: код, работающий с наследниками, может быть полностью несвязан с потенциально большим набором типов, реализующих данный интерфейс.
- Используйте коллекцию указателей:Если проблема кэширования вас не волнует — это самое логичное решение. Просто организуйте массив указателей на базовый класс или тип интерфейс. Вы можете полноценно использовать полиморфизм, а объекты могут быть любого размера.
- Это гибкое решение. Работающий с коллекцией код может работать с объектами любого типа, пока они поддерживают нужный вам интерфейс. Полная свобода.
- Это решение гораздо менее кэш-дружелюбное. Основная причина, почему мы обсуждали другие решения — это враждебная для кэша косвенность, создаваемая указателями. Но помните, что если код не является критически важным в плане производительности, то все в порядке.
Как определять игровые сущности?
Если вы используете этот шаблон в тандеме с шаблоном Компонент (Component), у вас вполне может существовать последовательный массив компонентов, представляющий сущности вашей игры. Игровой цикл будет обходить их напрямую, так что объект для игровой сущности не слишком важен, но может быть полезен в других частях кодовой базы, где вам захочется работать с отдельной концептуальной «сущностью».
Вопрос здесь в том — как представлять сущность? Как она будет следить за своими компонентами?
- Если игровые сущности — это классы с указателями на свои компоненты:Именно так выглядел наш первый пример. Это самое традиционное
ООПрешение. У вас есть класс дляGameEntityи у него есть указатели на свои компоненты. Так как все это просто указатели — остается только догадываться, где и как на самом деле размещаются эти компоненты в памяти.- Вы можете хранить компоненты в последовательном массиве. Так как игровой сущности все равно, где находятся ее компоненты, вы можете организовать их в хорошо упакованный массив для оптимизации из обхода.
- Получив сущность, вы легко можете добраться до ее компонентов. Для этого нужно просто перейти по указателю.
- Перемещать компоненты в памяти сложно. Когда компоненты включаются или выключаются, вы можете попробовать перемещать их внутри массива, так что активные будут находиться вначале, а неактивные в конце. Но если вы будете перемещать компонент, на который ссылается сущность — вы разрушите эту связь, если не будете действовать осторожно. Вам нужно будет обязательно обновить при этом и указатель на компонент внутри сущности.
- Если игровые сущности — это классы с
IDсвоих компонентов:Сложность работы с указателями на компоненты заключается в том, что при этом их становится сложнее перемещать в памяти. Вы можете применить более абстрактную адресацию:IDили индекс, который можно использовать для поиска компонента.СемантикуIDи реализацию поиска я оставляю на ваше усмотрение. Это может быть простойID, хранимый внутри компонента и обход массива или более сложное решение с применением хеш таблиц, связывающихIDс индексом компонента в массиве.- Это сложнее. Конечно ваша система ID не сравнится по сложности с ракетостроением, но работы явно больше чем при использовании обычных указателей. Вам нужно будет ее реализовать и отладить. А еще у вас появятся накладные расходы на бухгалтерию.
- Это медленнее. Сложно тягаться с сырыми указателями. Для того, чтобы получить компонент сущности, нам нужно будет выполнять поиск или какую-то операцию с хешированием.
- Вам потребуется доступ к «менеджеру» компонентов. Основная идея заключается в том, что у вас есть абстрактный
ID, идентифицирующий компонент. И вы можете использовать его, чтобы получить указатель на сам компонент. Но чтобы это сделать, вам нужен кто-то, кто может найти компонент по егоID. Это будет класс — обертка над сырым последовательным массивом компонентов наших объектов.При работе с сырыми указателями, если у вас есть сущность — значит вы можете получить и ее компоненты. В этом случае вам потребуется не только сама сущность, но и предварительная регистрация компонентов.Вы можете подумать: «Так я применю синглтон! И проблема решена!» Ну как бы да. Только советую сначала заглянуть в эту главу.
- Если игровые сущности представляют из себя всего лишь
ID:Это сравнительно новый способ, который применяется в некоторых игровых движках. Как только вы перенесете все поведение и состояние сущности из главного класса в компоненты, то что останется? Немного на самом деле. Единственное что делает сущность — это связывает вместе набор компонентов. Она нужна только для того, чтобы сообщать нам, что этотAIкомпонент, этот физический компонент и этот компонент рендеринга образуют игровую сущность в нашем мире.Важно здесь то, как компоненты взаимодействуют. Компоненту рендеринга нужно знать, где находится сущность. А эта информация может храниться в физическом компоненте. КомпонентAIхочет перемещать сущность и для этого ему нужно приложить силу к физическому компоненту. Каждому компоненту нужно иметь возможность получить доступ к родственному компоненту, вместе с которыми они образуют сущность.Думаю некоторые уже догадались, что все что нам нужно — этоID. Вместо того, чтобы сущность знала о своих компонентах, компоненты могут знать о своей сущности. Каждый компонент может знатьIDсущности, которой он принадлежит. КогдаAIкомпоненту потребуется физический компонент своей сущности, он просто запросит физический компонент с таким жеIDкак и у него.Ваши классы сущностей полностью исчезают, заменяемые удобной оболочкой над числами.- Сущности занимают мало места. Если вам нужно передать ссылку на игровую сущность — вы просто передаете число.
- Сущности пустые. Логично, что недостатком такого решения является то, что вам придется убрать из сущностей все. У вас больше нет места для хранения не компонентно-специфического состояния или поведения. Эти функции тоже возлагаются на шаблон Компонент.
- Вам не нужно управлять временем жизни. Так как сущности — это значения простых типов, их не нужно явно создавать или удалять. Сущность «умирает», когда уничтожаются все ее компоненты.
- Поиск компонентов сущности может быть достаточно медленным. Это та же самая проблема, как и в предыдущем решении, но немного с другой точки зрения. Чтобы найти компонент какой-либо сущности, вам нужно найти объект по
ID. Этот процесс может быть достаточно затратным.На этот раз поиск является критически важным для производительности. Компоненты часто взаимодействуют со своими родственниками во время обновления, так что искать их придется часто. В качестве решения можно сделать «ID» сущности индексом компонентов в массивах.Если у каждой сущности будет одинаковый набор компонентов, то все ваши массивы с компонентами будут полностью параллельными. Компонент в слоте три в массивеAIкомпонентов будет принадлежать той же сущности, что и физический компонент в массиве три в соответствующем массиве.Имейте ввиду, что вам придется затрачивать усилия для сохранения параллельности массивов. Это может быть сложным, если вам захочется сортировать или упаковывать их по разным критериям. У вас могут быть сущности с выключенной физикой и другие — невидимые. Поэтому не получится отсортировать физические и рендер-компоненты таким образом, чтобы массивы остались синхронизированными друг с другом.
Смотрите также
- Большая часть этой главы вращается вокруг шаблона Компонент (Component) и это определенно одна из наиболее часто используемых структур данных для оптимизации работы с кэшем. И действительно, применение компонентов этому способствует. Так как сущности обновляются по одной «области» (
AI, физика и т.д.) за раз, разбиение их на компоненты позволяет поделить сущности на более удобные в плане работы с кэшем кусочки.Но это не значит, что вы можете использовать этот шаблон только с компонентами! Каждый раз, когда у вас встречается код критический в плане производительности, работающий с большим объемом данных — подумайте о локальности данных. - «Ловушки объектно-ориентированного программирования» Pitfalls of Object-Oriented ProgrammingPDF Тони Альбрехта — это, наверное, самое лучшее чтиво на тему организации структур данных в игре в максимально кэш-дружественном виде. Я встречал много людей (включая меня самого), кому эта книга помогла с улучшением производительности.
- Примерно в то же время Ноэль Ллопис написал хороший пост в своем блоге на ту же тему.
- Этот шаблон практически полностью основан на использовании последовательного массива гомогенных объектов. Время от времени вам наверняка придется добавлять или удалять из него объекты. Шаблон Пул объектов (Object Pool) как раз этому и посвящен.
- Игровой движок Artemis — один из первых и наверное самый известный из фреймворков, использующих
IDв качестве игровой сущности.